Generative KI liefert Kontext? Ja klar, aber egal welches Modell, welcher Anbieter: Möchte man ein Word-Dokument oder eine Powerpoint-Präsentation, lassen sich diese häufig nicht öffnen oder enthalten nur Teile der Ausgabe. Das das einzige Dateiformat, das LLMs wirklich zuverlässig liefern, ist Markdown (*.md) – eine sehr simple, ursprünglich 2004 von John Gruber entwickelte Auszeichnungssprache, die mit einfachen Sonderzeichen Textformatierungen erlaubt. Doch die Alltagstauglichkeit von Markdown ist eher bescheiden, weil bislang kein Office-Paket, egal von welchem Hersteller, Markdown wirklich unterstützt (Hinweis: Für Februar 2026 ist LibreOffice v26 angekündigt, das als ein neues Main Feature die Markdown-Unterstützung mitbringen wird).
Eine sehr schöne Lösung stellt pandoc dar: Kommandozeilenbasiert wandelt es .md in .docx oder .pptx um:
Jedes beliebige Terminal kann benutzt werden, also Windows Terminal, der gute alte DOS-Prompt oder auch Powershell, im Terminal in VS Code gibt’s sogar Vorschläge von Github Copilot!
Ja, erfordert aber zusätzlich eine LaTEX-Installation, und da die meisten Dokumente ohnehin noch bearbeitet werden, wird hier der Weg über das eigene Office-Paket der elegantere sein.
Die Hardware ist vorhanden, die Umgebung ist aufgesetzt. Doch welches Modell von Hugging Face oder der Ollama Model Library passt denn jetzt in meine lokale Welt?
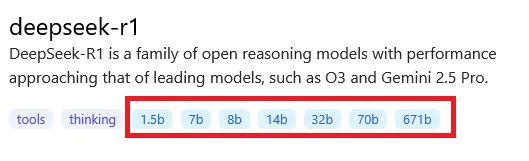
KI-Modelle in der Ollama Model Library oder von Hugging Face geben an, wieviele Parameter sie verwenden – je mehr Parameter, desto leistungsfähiger das Modell, wird angenommen. Mit Hilfe dieser Parameter-Zahl lässt sich abschätzen, welche Speicheranforderungen ein Modell an das eigene System stellt. Die Parameterzahl lässt sich entweder direkt aus dem Namen (z.B. „gpt-oss-20b“) oder aus der Beschreibung des jeweiligen Modells entnehmen – in der Ollama Model Library sind diese Werte direkt verlinkt zu den jeweiligen Modellen:
Die Amerikaner zählen „millions, billions, trillions“, anders als wir Europäer, die „Millionen, Milliarden, Billionen, Billiarden…“ zählen. Ein 2b-Modell hat also 2 Milliarden Parameter.
Ein Parameter entspricht grundsätzlich einer Variablen im Arbeitsspeicher, und da moderne Systeme normalerweise Fließkommzahlen als 32-bit-Werte speichern, entsprechend also 4 Byte je Parameter, sollte sich für ein Modell mit 2 Milliarden Parametern (ein 2b-Modell) ein Speicherplatz von 4 byte x 2 Milliarden = 8 Gigabyte ergeben?
Speicherplatzbedarf optimiert
Fast, aber nicht ganz! Dass der Speicherverbrauch eines Modells ein limitierender Faktor ist, hat auch die Entwicklergemeinde ganz schnell verstanden, und zwei ganz grundsätzliche Gegenmaßnahmen ergriffen:
Erstens reicht es für KI-Systeme meist aus, 16-bit-Fließkomma-Operationen (= 2 Byte) durchzuführen, was den Speicherbedarf gerade mal halbiert! Für nicht-quantisierte Modelle (siehe unten) gilt also folgende Tabelle für 16-bit-Fließkomma-Parameter:
Modellgröße
Speicherbedarf (ca.)
2b
4 GB
3b
6 GB
7b
14 GB
13b
26 GB
Zweitens können KI-Systeme „quantisiert“ werden, d.h. die Entwickler*innen des Modells legen die zu verwendende Bit-Breite selbst fest – und geben dies durch ein q-Suffix im Modellnamen an, z. B. ist „llama2:7b-q4“ – ein 7b-Modell mit 4-bit-Werten (= 0,5 Byte), also:
0,5 byte x 7 Milliarden = 3,5 Gigabyte.
Hierzu gibt es natürlich keine Tabelle, da ist selbst rechnen angesagt, nach folgender Formel:
Bit-Breite in Byte x Anzahl Parameter = RAM-Bedarf des Modells in Byte
In der Praxis können sich höhere Werte als berechnet ergeben, diese Formel liefert lediglich eine Orientierung.
Fazit
Modellname und Beschreibung geben Hinweise auf die Paramterzahl und damit den Speicherplatzbedarf eines Modells. Aktuelle Modelle verwenden 16-Bit-Fließkomma-Operationen, der Speicherplatzbedarf ist also über eine simple Formel bestimmbar. Als Besitzer eines Systems mit 16 GB RAM oder noch besser 16 GB VRAM der GPU kann man also Modelle bis 7 Milliarden Parameter (7b-Modelle) in seinem System verkraften, bei quantisierten Modellen je nach Bit-Breite auch deutlich mehr.
Digitale Kameras (ja, auch die in Handys!) schreiben beim Speichern einer Aufnahme eine ganze Reihe fotografisch relevanter Daten (Belichtung, ISO-Zahl, Brennweite, Blende, Kameramodell) als sog. EXIF-Daten in die Bilddatei – übrigens nahezu unabhängig vom Zielformat, sowohl RAW als auch JPG enthalten diese Daten. Und auch unabhängig vom Kamerahersteller, denn EXIF ist ein weltweiter Standard.
Allerdings, da das Speicherformat von Bildern immer ein binäres ist, werden die EXIF-Daten ebenfalls dort binär abgelegt, was das Auslesen etwas aufwändiger macht. Jedem EXIF-Tag (Belichtung, ISO-Zahl, Brennweite,..) ist eine hexadezimale Tag-ID zugeordnet, und jeder EXIF-Tag hat einen spezifischen Datentyp, ggf. sogar eine Auswahlliste fest vorgegebener Werte. Wer sich reinnerden will: https://exiftool.org/TagNames/EXIF.html.
Aber egal, ob für eine Bilddatenbank oder RAG für eine lokale KI, man kann den Job mit Powershell erledigen, wir bauen uns ein CmdLet Get-ExifData, das für ein gegebenes Bild die EXIF-Daten ausliest.
Zwei kleine Helper-Funktionen
Ich kann mich an eine Auftragsarbeit in C# vor Jahren erinnern, wo das Auslesen der EXIF-Daten in eine ziemliche Konvertierungsorgie eskalierte. Powershell ist da freundlicher, weil es viele Konvertierungen implizit vornimmt. Trotzdem erstellen wir uns eine kleine Konvertierungsfunktion für die wichtigsten Datentypen, auf die wir treffen werden – Byte, ASCII, short, long, rational (Fließkomma):
Und weil beim rational-Datenformat jemand ganz kreativ war (es stellt eigentlich einen ganzzahligen Bruch dar: Die ersten 4 Bytes sind der Zähler, die zweiten 4 Bytes der Nenner), hier noch eine zusätzliche Konvertierung, damit daraus ein in Powershell verwendbarer double wird:
Diese Liste kann natürlich beliebig erweitert werden, hier wurden nur die wichtigsten der gut 80 EXIF-Tags ausgewählt.
Die eigentliche Skript-Logik
Und dann kann es auch schon losgehen: $Image enthält den vollständigen Pfad zu einer Bilddatei, aus der wir ein System.Drawing.Image machen. Diese .NET-Klasse stellt uns die EXIF-Daten als PropertyItems zur Verfügung, über die wir iterieren und nach „unseren“ TagIDs suchen. Bei einem Treffer kommt unsere Get-ExifValue Funktion zum Einsatz, und wir schreiben den nun für Powershell lesbaren Wert in unsere Ergebnisdaten $exifData.
if (-not (Test-Path$Image)) {Write-Error"File not found: $Image"return }try {$imageObj = [System.Drawing.Image]::FromFile($Image)# Hashtabelle für EXIF-Daten$exifData = [ordered]@{}# Die EXIF-Daten sind PropertyItems des Image-Objektsforeach ($propin$imageObj.PropertyItems) {# Konvertiere die numerische Property-ID in einen 4-stelligen Hexadezimal-String (z.B. 0x829A)$id = '{0:X4}'-f$prop.Id# Verwende einen sprechenden Namen aus $exifTags, falls verfügbar, sonst einen generischen Namen$name = $exifTags[$prop.Id] ?$exifTags[$prop.Id] : "Unknown_0x$id"# Dekodiere den Property-Wert mit der Hilfsfunktion, abhängig vom Typ$value = Get-ExifValue$prop# Speichere den Property-Namen und den dekodierten Wert in der Hashtabelle$exifData[$name] = $value }$imageObj.Dispose()# Gib alle EXIF-Daten als PowerShell-Objekt aus [PSCustomObject]$exifData }catch {Write-Error"Could not read EXIF data from $Image. $_" }
Weil Speicher begrenzt ist, wird am Ende noch das Image entsorgt (Dispose()), und weil Dateizugriffe kleine Zicken sind, liegt das Ganze in einem robusten Try...Catch Block.
Das fertige CmdLet im Ganzen
Und hier nochmal das ganze Skript verpackt in ein CmdLet Get-ExifData:
functionGet-ExifData { [CmdletBinding()]param ( [Parameter(Mandatory, Position = 0, ValueFromPipeline, ValueFromPipelineByPropertyName)] [Alias("FullName")] [string]$Image )begin {$exifTags = @{0x0100 = "ImageWidth"0x0101 = "ImageHeight"0x010F = "Make"0x0110 = "Model"0x0112 = "Orientation"0x0132 = "DateTime"0x829A = "ExposureTime"0x829D = "FNumber"0x8833 = "ISOSpeed"0x9003 = "DateTimeOriginal"0x9201 = "ShutterSpeedValue"0x9202 = "ApertureValue"0x9204 = "ExposureBiasValue"0x9209 = "Flash"0x920A = "FocalLength"0xA002 = "PixelXDimension"0xA003 = "PixelYDimension"0xA405 = "FocalLengthIn35mmFilm"0xA432 = "LensSpecification"0xA434 = "LensModel"0xA420 = "ImageUniqueID" }functionConvert-Rational {param ($bytes)$num = [BitConverter]::ToUInt32($bytes, 0)$den = [BitConverter]::ToUInt32($bytes, 4)if ($den -eq 0) { return$num }return [math]::Round($num / $den, 4) }functionGet-ExifValue {param ($prop)switch ($prop.Type) {1 { return$prop.Value[0] } # BYTE2 { return ([System.Text.Encoding]::ASCII.GetString($prop.Value)).Trim([char]0) } # ASCII3 { return [BitConverter]::ToUInt16($prop.Value, 0) } # SHORT4 { return [BitConverter]::ToUInt32($prop.Value, 0) } # LONG5 { returnConvert-Rational$prop.Value } # RATIONAL7 { return$prop.Value } # UNDEFINED9 { return [BitConverter]::ToInt32($prop.Value, 0) } # SLONG10 { returnConvert-Rational$prop.Value } # SRATIONALdefault { return$prop.Value } } } }process {if (-not (Test-Path$Image)) {Write-Error"File not found: $Image"return }try {$imageObj = [System.Drawing.Image]::FromFile($Image)# Hashtabelle für EXIF-Daten$exifData = [ordered]@{}# Die EXIF-Daten sind PropertyItems des Image-Objektsforeach ($propin$imageObj.PropertyItems) {# Konvertiere die numerische Property-ID in einen 4-stelligen Hexadezimal-String (z.B. 0x829A)$id = '{0:X4}'-f$prop.Id# Verwende einen sprechenden Namen aus $exifTags, falls verfügbar, sonst einen generischen Namen$name = $exifTags[$prop.Id] ?$exifTags[$prop.Id] : "Unknown_0x$id"# Dekodiere den Property-Wert mit der Hilfsfunktion, abhängig vom Typ$value = Get-ExifValue$prop# Speichere den Property-Namen und den dekodierten Wert in der Hashtabelle$exifData[$name] = $value }$imageObj.Dispose()# Gib alle EXIF-Daten als PowerShell-Objekt aus [PSCustomObject]$exifData }catch {Write-Error"Could not read EXIF data from $Image. $_" } }}Export-ModuleMember -Function Get-ExifData# Anwendung:# Import-Module ".\Get-ExifData.psm1"# Get-ExifData -Image "C:\Path\To\Your\image.jpg"
In meinen Seminaren und Beratungen oft Thema: Was genau bedeuten eigentlich die Lizenzen, die jedem nuget-Paket mitgegeben werden? Muss man sich darum kümmern?
Die zweite Frage beantwortet sich eigentlich ganz einfach: Wenn Lizenzbedingungen nicht wichtig wären, wären sie nicht angeben! Da die meisten meiner Kunden gewerblich Software entwickeln, kann die Nichtbeachtung von Drittlizenzen richtig teuer werden.
Die Lizenzangaben zu den nuget-Paketen regeln, inwieweit und zu welchen Bedingungen ein nuget-Paket in einem Softwareprodukt verwendet werden darf, ob und zu welchen Bedingungen ein Paket verändert werden darf, und in einigen Fällen auch, wie die Weitergabe des Pakets im Deployment auszusehen hat.
Liste der häufigsten Lizenzmodelle
Hier die am häufigsten verwendeten Lizenzen auf nuget.org, ohne Anspruch auf Vollständigkeit:
MIT Lizenz
Beschreibung: Sehr permissive Lizenz. Die Software darf frei genutzt, verändert, kopiert und sogar in kommerziellen Produkten verwendet werden.
Bedingungen: Der Lizenztext muss beigefügt werden.
Eignung: Unproblematisch für kommerzielle und nicht-kommerzielle Nutzung.
Apache License 2.0
Beschreibung: Sehr frei, erlaubt Nutzung, Modifikation und Vertrieb, auch kommerziell.
Bedingungen: Lizenztext und Copyright-Hinweis müssen erhalten bleiben. Bei Änderungen muss angegeben werden, was geändert wurde. Es gibt eine explizite Patentklausel.
Eignung: Unproblematisch für kommerzielle und nicht-kommerzielle Nutzung.
BSD License (meist 2-Clause oder 3-Clause)
Beschreibung: Sehr ähnlich wie MIT, mit leichten Unterschieden bei Haftungsausschluss und Werbung (Details im Lizenztext).
Bedingungen: Lizenztext muss unverändert weitergegeben werden, es darf keine Werbung mit dem Paket oder dem Namen des Rechteinhabers gemacht werden (3-Clause).
Eignung: Unproblematisch für kommerzielle und nicht-kommerzielle Nutzung.
GPL (General Public License)
Beschreibung: Strikte Copyleft-Lizenz. Jede Software, die GPL-Code nutzt, muss selbst unter der GPL veröffentlicht werden!
Bedingungen: Wer ein GPL-Paket verwendet und die Software verteilt, muss den Quellcode seiner Software ebenfalls unter GPL offenlegen!
Eignung:Nicht geeignet für proprietäre oder kommerzielle Software, wenn man den Quellcode nicht veröffentlichen will. Für Open Source-Projekte geeignet.
LGPL (Lesser General Public License)
Beschreibung: Weniger strikt als GPL. Erlaubt die Nutzung in proprietärer Software, solange die LGPL-Komponente getrennt bleibt (z. B. als DLL).
Bedingungen: Änderungen am LGPL-Code müssen veröffentlicht werden.
Eignung:Mit Einschränkungen für kommerzielle Nutzung möglich, solange man sich an die Bedingungen hält.
Proprietäre/Eigene Lizenzen
Beschreibung: Der Rechteinhaber gibt individuelle Bedingungen vor. Häufig sind Einschränkungen bei kommerzieller Nutzung oder Verteilung enthalten. Hier hilft nur Lesen!
Eignung:Nur nach Prüfung der Lizenzbedingungen bedenkenlos nutzbar!
Public Domain
Beschreibung: Software ohne jegliche Lizenzbeschränkungen („gemeinfrei“).
Eignung:Bedenkenlos für alle Anwendungsfälle.
TL;DR
Zusammenfassend lässt sich sagen: Für kommerzielle Softwareentwicklung eignen sich MIT, Apache 2.0, BSD und Public Domain.
Mit Vorsicht zu verwenden sind LGPL und proprietäre Lizenzen, in beiden Fällen sollte eingehend geprüft werden, ob sich diese Lizenzen verwenden lassen. Ggf. wäre hier die Prüfung durch die Rechtsabteilung (wenn vorhanden) oder einen Fachanwalt ratsam.
GPL kommt nur dann in Frage, wenn der eigene Quellcode auch bedenkenlos unter GPL veröffentlicht werden kann. Dies ist bei kommerzieller Software selten der Fall.
Tipp: Viele Entwicklerteams legen sich ein eigenes, lokales nuget-Repository an, in dem nur die Pakete zur Verfügung gestellt werden, deren Lizenzbedingungen zu den Produkten des Hauses passen, und entfernen in Visual Studio das standardmäßig vorhandene nuget.org-Repository.
Selbst erfahrene C#-Entwickler kann man mit Fragen nach Stack und Heap ins Schwimmen bringen. Deshalb hier ein kurzer Refresher zu dem Thema.
Stack – der kleine, schnelle Speicher
Der Stack ist ein sehr schneller, linearer Speicherbereich, der vom Betriebssystem für jeden Thread bereitgestellt wird. Er wird für die Verwaltung von lokalen Variablen und Funktionsaufrufen genutzt. Hier speichert .NET/C# Werte von Werttypen (wie int, double, bool, structs), die als lokale Variablen in Methoden deklariert sind. Außerdem werden hier Funktionsaufrufe (Call Stack, Rücksprungadressen, lokale Variablen) abgelegt. Speicher in diesem Bereich wird automatisch freigegeben, sobald eine Methode verlassen wird, aber das Betriebssystem begrenzt den Speicher standardmäßig auf 1 MB pro Thread (ASP.NET Core: 256KB), wenn der Entwickler nichts anderes angibt. Stack-Variablen existieren also nur so lange wie die entsprechende Methode aktiv ist.
Heap – der Objektspeicher
Der Heap ist ein Speicherbereich für die dynamische Verwaltung von Daten. Hier werden Referenztypen abgelegt, also Objekte und Arrays – und alle Daten, die über die Lebensdauer einer Methode hinaus existieren sollen. Theoretisch ist der Heap nur durch die Größe des RAM der Maschine begrenzt. Die Speicherverwaltung erfolgt hier durch den Garbage Collector von .NET: Nicht mehr benötigte Objekte werden automatisch freigegeben, die Lebensdauer von Daten ist nicht an die Lebensdauer von Methoden gebunden.
Der Konstruktoraufruf new Chicken() reserviert im Heap einen Bereich für die Daten des Huhns. Die Variable huhn jedoch ist eine lokale Variable und liegt daher auf dem Stack. Aber: huhn enthält nicht die Daten des Objekts, sondern nur die Adresse (Referenz), wo die Instanz im Heap gespeichert ist. Das Gewicht des Tiers, obwohl ein Wertetyp (int, double,...), liegt ebenfalls im Heap, weil es Teil des Objekts Chicken ist! Noch einen Schritt weiter geht die Name-Property unsers Huhns, denn die Chicken-Instanz enthält in ihrem Heap-Bereich einen Zeiger(!) auf das eigentlich String-Objekt, das ebenfalls im Heap zu finden ist. Kurz gesagt: Außer der Variable, die auf die Objekt-Instanz verweist, liegen bei Referenztypen alle Daten im Heap! Und weil der Heap von der Garbage Collection verwaltet wird, ist in C# im Zweifel explizites Disposing bei komplexeren Objektstrukturen immanent wichtig.
Neulich hatte ich das Vergnügen, mich mit dem guten alten Wakeup-On-LAN (WOL) auseinandersetzen zu dürfen. Die Doku schreibt etwas von einem „Magic Paket“, das gesendet wird, um den Rechner aufzuwecken.
Und weil Magie und Powershell sich irgendwie ganz gut vertragen, kurz mal tiefer eingelesen und gelernt, dass es sich dabei um ein simples UDP-Paket handelt, das an die MAC-Adresse des zu weckenden Rechners gesendet wird.
Voraussetzung ist, dass der zu weckende Rechner entsprechend für Wakeup-On-LAN konfiguriert ist (siehe BIOS-Einstellungen). Außerdem funktioniert die Wakeup-On-LAN nicht, wenn der Rechner im Hibernate-Zustand ist. Komplett heruntergefahren oder Standby sind Zustände, aus denen er aufwachen kann.
Es kann sehr nützlich sein, mehrere Instanzen eines Datenbanksystems auf einer Maschine zu betreiben, und sei es nur, um in sehr kleinem Umfeld Produktion und Entwicklung von einander getrennt zu halten.
Wer Microsofts SQL Server benutzt, startet einfach den Installer neu und legt eine weitere Instanz an. PostgreSQL geht hier einen eigenen Weg: Die von einer Instanz verwalteten Datenbanken bezeichnet PostgreSQL als Database Cluster, und so ein Cluster ist nichts anderes als ein weiteres Datenverzeichnis – das jedoch mit einem eigenen Dienst und zugehörigen Port ausgestattet werden will.
Die Schritte in Kürze:
Anlegen des neuen Datenverzeichnisses (initdb)
Konfigurieren des Ports (postgres.conf)
Initialisieren des Dienstes (pg_ctl)
Dienst starten
Wir starten mit dem Anlegen des Datenverzeichnisses. Dazu braucht der verwendete Benutzer die Rechte zum Anlegen neuer Verzeichnisse sowie zum Verwalten von Diensten, am besten ein (lokaler) Admin. In einer Eingabeaufforderung/Powershell benutzen wir dafür initdb aus den Postgres-Binaries:
Der Switch -D erwartet die Angabe des gewünschten Datenverzeichnisses (hier C:\Data\pgdata2). An dieser Stelle das Installationsverzeichnis von PostgreSQL anzugeben, ist keine gute Idee, besser, man legt ein eigenes Verzeichnis an, wenn nicht schon längst geschehen.
InitDb macht genau das, was der Name suggeriert: Es legt im angegebenen Verzeichnis alles an, was PostgreSQL benötigt:
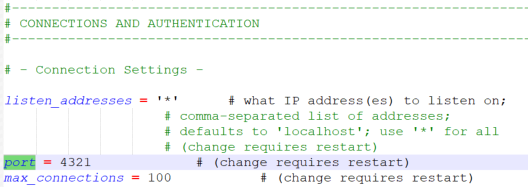
Damit dieser Cluster erreichbar wird, benötigt er die Angabe eines Ports in der postgresql.conf im gerade angelegten Verzeichnis: Wir öffnen also C:\Data\pgdata2\postgresql.conf mit einem Editor unserer Wahl und tragen einen Port ein, der noch nicht verwendet wird:
Vor dem Speichern ggf. noch schnell den Eintrag listen_addresses einkommentieren, sonst kommen wir trotz aller Portangaben nicht auf die Instanz. Da der zugehörige Dienst noch nicht existiert, können wir die Kommentare zum Neustart ignorieren.
Als nächstes starten wir den passenden Server: Initialisieren des Serverdienstes mit pg_ctl – in einer Eingabeaufforderung/Powershell mit entsprechenden Rechten
pg_ctl register -N <Name des neuen Postgres-Dienstes> -D <Datenverzeichnis>
Der Switch -N will den Namen des neuen Dienstes, -D gibt wieder das Datenverzeichnis an.
War das erfolgreich, können wir den Dienst starten:
net start PostgresDevService
Der Datenbank-User für Verbindungen zu dieser neuen Instanz ist zunächt der Windows-User, unter dem wir dies alles gerade durchgeführt haben (also nichtpostgres!), das Passwort entsprechend das dazugehörige Windows Passwort. Wer hier mehr/anderes braucht, kann nun in der neuen Instanz Rollen und Rechte anlegen, zuordnen und verwalten (siehe PostgreSQL-Doku).
Tipp bei Verbindungsproblemen, insb. remote:pg_hba.conf regelt, von welchen IP-Adressen wie zugegriffen werden darf (PostgreSQL Doku), und die Windows-Firewall redet natürlich auch noch ein Wörtchen mit…
Cookie-Zustimmung verwalten
Wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.